 |
 |
| Google n-grams viewer | Tool 1 built by students on this assignment: 1-gram history viewer |
Automated testing suite, solutions, and script for generating datasets from the official (much larger) Google dataset also available upon request by email.
The Google Ngram database provides ~3 terabytes of information about the frequencies of all observed words and phrases in English (or more precisely all observed kgrams). Google provides the Google Ngram Viewer on the web, allowing users to visualize the relative historical popularity of words and phrases.
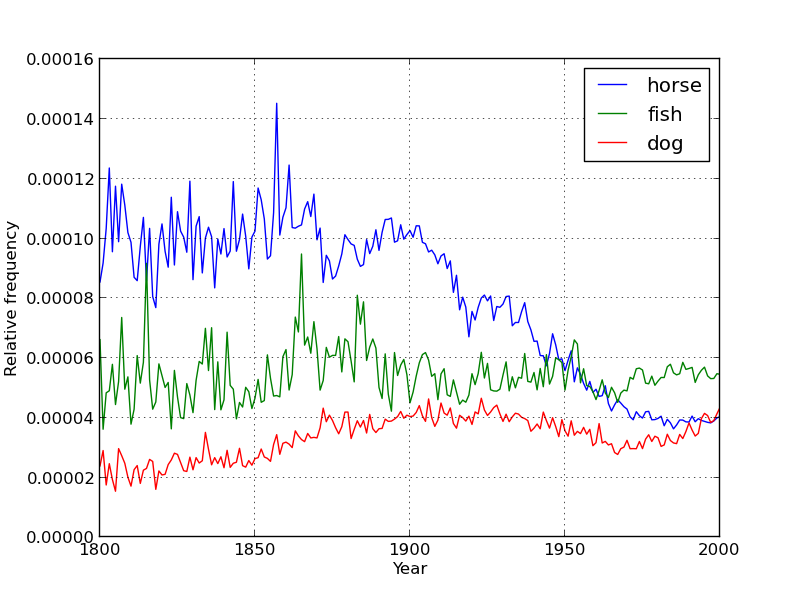
In this assignment, students will build their own version of the Google Ngram Viewer for 1grams. They will then build three additional visualization tools to explore other aspects of the dataset that cannot be addressed using the Google Ngram Viewer.
|
|
|
| Google n-grams viewer | Tool 1 built by students on this assignment: 1-gram history viewer |
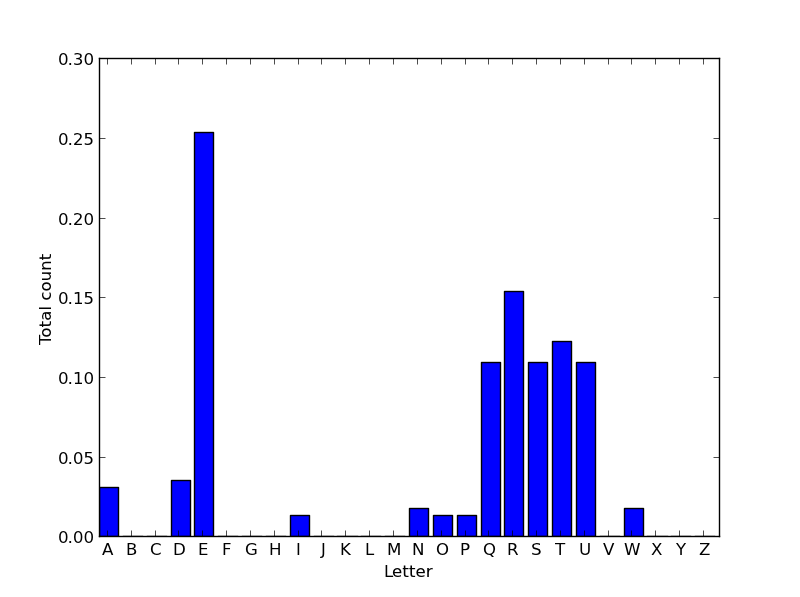
The three additional visualization tools include the distribution of letters in the English language, the distribution of all word frequencies in English, and the length of the average word in English since the 1800s. Examples of each are shown below (with a restricted dataset to avoid spoilers).
Students will observe a roughly linear relationship on the plot. It is a surprising fact that the frequency of words and their rank should obey a power law. This is known as Zipf's law.
| Summary |
Students parse Google's 1-gram dataset and store information in two different data structures. Using the first (and simpler) data structure, students create a tool for visualizing the relative historical popularity of a set of words (resulting in a tool much like Google's Ngram Viewer). Using the second (and more complex) data structure that includes the entire dataset, students build three tools that deal with aggregate properties of the data. Specifically, they build tools for visualizing the letter frequences of words in English, for observing the distribution of popularities of all English words (thus revealing Zipf's law), and for visualizing the average length of a word in English from the 1800s to present (revealing an interesting result). |
| Topics |
string processing, arrays, associative arrays, file I/O, visualization |
| Audience |
CS1 |
| Difficulty |
Intermediate. The entire assignment took 8 to 12 hours for students to complete (spread over two weeks). Length of assignment can be reduced by removing one or more of the visualization tools from the assignment.
|
| Strengths |
Students liked being able to recapitulate a cool Google tool after only three weeks of programming experience. There are lots of interesting things to learn from the dataset using the tools that students develop. This dataset is actively being probed by researchers around the world, making it easy to steal ideas for further tools (see variants section below for more), including non-visual tools. |
| Weaknesses |
Functions are described at a high level, and weaker 1st-semester CS students may have a hard time conceptualizing how to convert these functions into well-organized code. For example, when counting up the frequencies of letters in English, they have to figure out that they need to store 26 counters, and further that these 26 counters must each be normalized by the sum of all of these counters. Diversity of dataplot types so early in the course results in a significant amount of new syntax. Assignment materials attempt to address this by providing hints throughout. The provided 100 megabyte dataset is only a small subset of the full 1-grams dataset, so students may be slightly disappointed to find that modern colloquialisms and niche terms may not appear. #swag |
| Library Dependencies |
Requires matplotlib in Python (easy to install using widely available binaries). If adapted for another programming language, requires a simple but powerful visualization library. |
| Variants |
Giving specific scientific and historical queries to answer with their tools could be a neat addition (e.g. do peaks in the term 'influenza' correspond to historical influenza outbreaks?) For more advanced students, the assignment could be expanded to include additional and more complex visualization tools.See this page for a few good ideas. |