- Introduction
- Problem Statement
- Document Sets
- Assignment Sheet
- Comments
- "Nifty" Meta-data - click link for more
- Contact Info
| find the plagiarized documents in a set | |
| I/O, many data structures (see below) | |
| CS1/CS2 | |
| depends, full bore is hard | |
| actual thinking involved | |
| assesment is a challenge | |
| knowledge of data structures | |
| many (see below) |
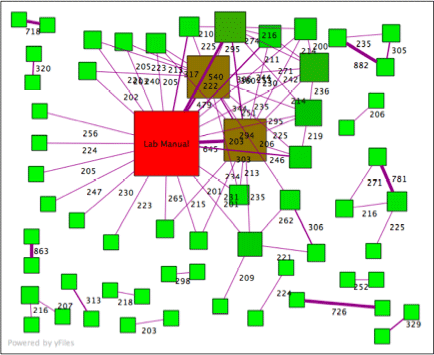
Visualization of a solution: lines represent number of common word
sequences between files. Can you find the plagiarists?
Introduction
This lab presents a real problem that really requires a software solution...neato!
Problem Statement
Catch the plagiarists! Your goal is to try to (quickly) determine the similarities between documents in a set to see if you can find out if plagiarism is going on within the group.
More formally: given a set of text documents (see below), try to determine whether or not, or the degree to which, any pair of documents contains heavily copied portions of text. If one document shares an inordinate number of phrases in common with another, it's likely the document is plagiarized (or is the result of the all-too-often occurrence of finding out that one student "helped" another by giving him a copy of his work, only to have the other turn it in as his own).
Document Sets
- BigDocSet.zip - 1,354 docs -- ~1,615,193 words
- MedDocSet.zip - 75 docs -- ~91,273 words
- SmDocSet.zip - 25 docs -- ~33,946 words
- Notes about the documents:
- All documents are (usually bad) "high school" essays pulled from the website www.freeessays.cc. There may still be some lingering html floating around some documents.
- This is D.I.Y. plagiarism, for the most part. Each set contains one plagiarized documet called catchmeifyoucan.txt. I suggest concocting your own plagiarism scheme, creating your own plagiarized documents out of the big set, and letting your students try to find them.
- "medium" and "small" sets of documentts are just subsets of the big document set.
Sample Assignment Sheet
Really, all you need is the problem statement and the document sets. I provide here a sample assignment sheet which gives my students some direction if they're feeling totally overwhelmed. It also shows the milestones I use to make sure they're making progress (these milestones really need some work. If you come up with better milestones please email me to let me know what you did).
Comments
Really, this assignment is quite accessible for first-year CS students. It's fantastic to watch the students really grapple with the pros and cons of making certain design decisions. Students seem to understand afterward that a.) there are MANY different ways the same problem can be attacked both good and bad and b.) design is hard, but worthwhile. And students really do go after this assignment because there's a hook: they want to find the plagiarized documents in the set that I give them. It's like hide and seek.
I would like to give credit to Ross O'Connell (PhD Candidate, University of Michigan, Physics Dept., Particle Theory Group) for alerting me to this problem.
Other Nifty Meta-data
Topics
Assignment can be modified to cover one, a few, or many CS1/CS2 topics including file I/O, text parsing and most importantly, designing and applying data structures. You can even delve into some difficult graphics issues if you want to go that route. Depending on the strategy a student uses issues of sorting may also come to the fore. As a capstone-type project it can require application of all topics typically taught in CS1/2.
Audience
Probably appropriate for CS2ish-type-people. But a less-deep version could easily be concocted for the latter part of a CS1 class. The more data structures the students know, the more interesting and rewarding they'll find the assignment.
Difficulty
Difficulty depends how open you leave the assigment. I present it as a real-world problem to my students without any CS mumbo-jumbo and allow them to creatively apply what they know - really, I give them the problem statement, point them to the document sets and let 'em go. This approach is very rewarding for the students but it does take more time.
You could concievably provide students with some of the work already done in order to allow them to focus on one particular aspect of the problem. For example: do the text parsing for them so they can get down to the work of designing data structures.
I give my H.S. students about four weeks to do this assignment with milestones that need to be achieved each week. Two weeks is probably appropriate at the university level. You could conceivably do it in pieces if you want tighter control over where students will go with it.
Strengths
This assignment seems to hit the sweet spot between a toy-application and real-world problem. As a teacher I love it because it really forces burgeoning CS students to think deeply about choosing an efficient algorithm to solve the problem and designing data structures to support it. It's also a neat way to show how a good algorithm/data structure can make all the difference in the world.
This assignment's greatest strength is that it offers a lot to a highly differentiated group of students and abilities. It's a deep problem that's easy to state, intriguing and do-able for a wide range of students. Students who are just trying to pass can get by with good results, and know-it-alls are confronted with some real-world issues that are challenging to tackle. The most adventurous students also try to produce a graphical GUI and graphical output (as pictured above and in the assignment sheet).
Weaknesses
Part of the reason I'm submitting this assignment to Nifty is because I have not found a tremendous weakness, but here are some things that can be difficult:
- At some point students are forced to deal with the vagaries of file I/O. I actually think this is a strength, but it can be not very much fun without the correct amount of guidance.
- Solving the problem (efficiently and stably) for a the large set of data is VERY hard using the structures CS1/CS2 students have been exposed to. Doing the minimum requirements is achievable for almost any student, but even talented and motivated students might not see success for large inputs. Some find this frustrating. (Again, I don't see this as a weakness).
- Staggered assesment is a challenge. I haven't really come up with good assesment milestones that really allow students to know that they're making good progress. I teach relatively small classes so I can get away with this, but for larger classes it could be a challenge. Please help me with this :)
- Assesment can also be a pain because of some of the "creative" approaches students take. If you're planning to assess their design as well as correctness, well, don't make any plans. You can avoid this by trying to check students' design along the way.
Dependencies
Requires an introductory understanding of common data structures and algorithms. This assignment is really about intelligent application of common data structures and algorithms - students will be forced to reckon with the implications of choosing one strategy and/or data structure over another. As such, it's helpful to have library classes (like those in java.util) at your disposal.
Variants
Variation is built into the assignment since there are so many facests to it. If you don't want your students to do the whole thing from scratch you can have them just do pieces of it to focus on a particular subject. Choices abound at every turn. It can be just an I/O assignment, or just a text parsing assignment. You can provide them with the text parsing already done and make it an assignment to compare/contrast data structures. It can be an assignment about memory management and using the file system to handle large programs. You could do this in parallel! You could simply use the data generated as the basis of an interesting graphics assignment. Lots of options.
Contact Info
Baker Franke
Computer Science Dept.
The University of Chicago Laboratory Schools
1362 E. 59th St.
Chicago, IL 60637
bfranke@uchicago.edu