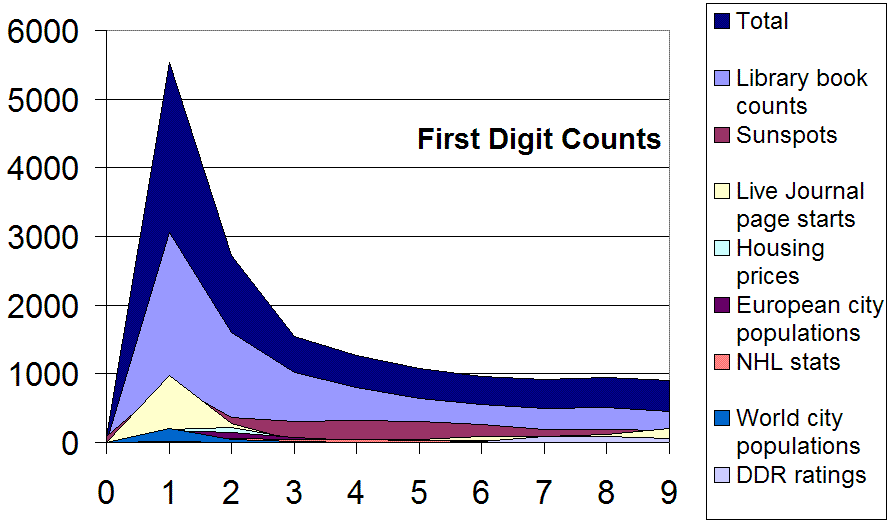
This assignment explores Benford's Law. The law describes a surprising pattern in the frequency of occurrence of the digits 1–9 as the first digits of natural data. You might expect each digit to occur with equal frequency in "arbitrary" data. Indeed, in truly random data (over appropriate ranges) each digit does appear with equal frequency. However, a substantial amount of natural data from sweepingly diverse sources does not exhibit a uniform distribution. Instead, 1 is more common than 2, 2 more common than 3, and so forth. The image in the upper right illustrates this trend with some disparate data. The trend is most obvious in the aggregate frequency across all the data.
Many thanks to the students and staff of Computer Science 312 at UBC during 2004–2005 for helping to develop, critique, and collect data for this assignment.
| Summary | Natural Prestidigitation
— write a simple number-crunching program to explore a bizarre phenomenon in the distribution of first digits of numerical data (called Benford's
Law) in real, student-collected data. |
| Topics |
Simple, mathematically-focused,
procedural-style programming. Uses loops, conditionals, integer
division, modulo, and a bit of arrays and I/O. |
| Audience |
Appropriate for intro programming. (Originally designed for a third year functional programming course.) |
| Difficulty |
A fairly easy assignment,
doable in 6 hours outside class for students most of the way
through CS1. (3rd year UBC students just learning their first
functional programming language finished in an average of 4
hours outside of class, including data collection.) |
| Strengths |
This is a simple, solid
practice problem of the sort our students often request. The
niftyness comes with the Benford's Law tie-in, which gives
students a taste of the power of computing in scientific
exploration, uses real data that students collect on their own,
and reveals a fascinating natural property of numbers. Also
your only opportunity to explain that logarithms once came in
books and catch financial fraudsters in one fell assignment!
(For more on both, see the resources
below.) |
| Weaknesses |
Unlike most nifty assignments,
this one appears rather dull. Even once under the
surface, not all students will find the mathematics of nature
exciting! Finally, the non-central use of arrays impedes use of
the assignment earlier in CS1. |
| Dependencies |
Requires a good grasp of
integer division and modulo. Requires some sophistication with
loops and conditionals: although no nested loops/ifs and no
complex conditions are used, the edge cases can be tricky.
Requires basic ability to understand, write, and use functions.
Makes very light use of I/O and a one-dimensional array. Works
fine in any language. |
| Variants | Various concepts can be emphasized or de-emphasized with minor changes:
|
Here's some sample data files to get you started:
Instead, this assignment offers three nifty features:
That said, to milk the niftyness of this assignment, it is absolutely crucial that you introduce it and wrap it up carefully. In your introduction, make clear that, while the assignment seems straightforward, the code they write has the potential reveal some fascinating properties of real data in the world around us! Ask students to predict a distribution of first digits in real data and why that distribution should occur.
In your conclusion, bring together as many sets of submitted student data as possible and graph them individually and as a combined set. Talk about the pattern that emerges. Discuss anomalies and their effect on the overall pattern! (For example, one of my students found housing prices for a certain neighborhood. Most data was in a very tight range, so that many first digits appeared rarely. Nonetheless, for the range represented, the first digits followed Benford's Law well!) Discuss Benford's Law and point students at some web resources for further inquiry if they're interested.
P.S. Several people have used the title "Looking Out For Number One" for Benford's Law related articles. I didn't use that title because I didn't think of it until I saw others' work with the name. Still, it's a better name than "Natural Prestidigitation". You make your own choice :)
Extra info about this assignment: