Nick Parlante, nick.parlante@cs.stanford.edu, Stanford University SIGCSE Nifty Assignments, 2005. (Back to Nifty Assignments)
| Summary | Name Surfer is a program that reads in and displays data from the Social Security Adiministration on the 1000 most popular baby names every decade for the last 100 years. The code is fairly straightforward, but the program enables access to a pretty entertaining data set. |
| Topics |
Basic coding: loops, abstraction,
reading data from a file, storing objects in a collection, basic
GUI controls and drawing. There are many layers of iteration
at work, although good abstaction isolates much of it.
The logic to draw the line
for one name is probably the hardest algorithmic part --
getting the scaling
and the decade markers and everything looking right. |
| Audience |
Late CS1 or anywhere in CS2 |
| Difficulty |
Medium difficulty and size. Algorithms involve
looping over moderately complex data, but nothing super complex.
The project is too big to be done in 1 week --
maybe allow 2 weeks in CS1, maybe due in two parts. |
| Strengths |
The coding is straightforward but the baby-name data the program brings to life is fun to play with. The project has an "Astrachan's Law" strength, where their code slices and dices through such a mass of data, it makes the whole thing fun. Shows off a basic sort of MVC structure, where the model contains the mass of data, and the view draws a subset of the model. |
| Weaknesses |
The project is not small.
Maybe have it due in 2 parts?
We use a handout that lays out the overall structure for them.
It does not require especially complex algorithms or decomposition.
|
| Dependencies |
Works fine in Java, and would
work in any GUI system -- just does ordinary things. |
| Variants |
In this version, the data
is presented in a single text file. In reality, the data is buried
in HTML tables at the SSA site. Could make the students parse
the raw HTML. Could provide the GUI code to them, although the drawing
itself is the hardest part, so if that's provided there's not much left.
Could hook up with the IMDB for data mining -- try to find trends
in baby-names that match-up with actors or characters in movies
of the day. Could |
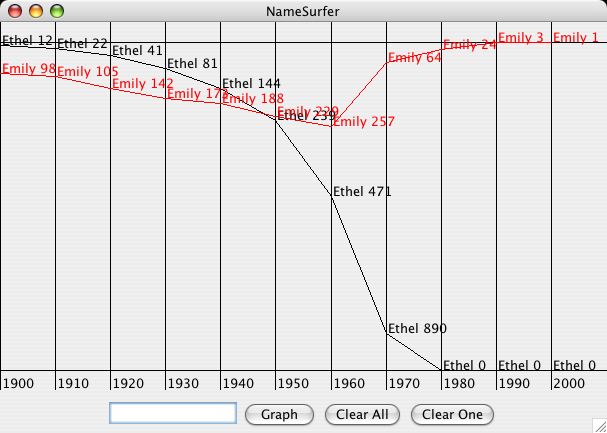
NameSurfer loads in historical data on popular baby-names for the last 100 years. You can type in a name, and it graphs the rank of that name over time. A high ranking, like 5, means the name was the 5th most popular that year (top of the graph), while a low ranking like 879 means the name was not that popular (bottom of the graph).
The handouts we use at Stanford desribe a possible solution strategy in some detail and in particular lay out the rough MVC structure we have them use: handouts
Extra info about this assignment: